

This is a continuation of The Taming of the Skew - Part One. Please read that first otherwise the rest of this post won’t make any sense!
Firstly, I’ve had a number of people ask when I would be publishing this blog post, so I’d like to apologise for the extremely long amount of time it’s taken me to do so. We’ve been very busy in Data Engineering with a big platform migration (among other things), the result of which is we’re now using Azure Databricks for all of our interactive and production Spark workloads. I mention this because it’s massively simplified how we deal with data skews, and if you’re lucky enough to be using either Azure Databricks or Databricks in AWS, you can probably just stop reading now, because you have access to a skew join hint.
If you are using Databricks but didn’t realise there was such thing as a skew join hint, I’ll just share these links:
- SQL: https://docs.databricks.com/delta/join-performance/skew-join.html
- Scala: https://kb.databricks.com/data/skew-hints-in-join.html
But for those of you who aren’t using Databricks, don’t despair - I’ll now discuss a more general approach to skew-fighting as planned (and from studying the execution plan with the skew hint on, it looks like it works a similar way under the hood 🕵️)
A more generic way of handling data skews
In part one, I discussed how if you had a discrete column in your data, you could use it to improve the distribution of your data (and ultimately, the performance of the join). But you’re probably thinking “that’s all well and good, but I don’t have a discrete column to use”.
So I’ll now describe a second technique. The underlying principle is the same, but we use a random salt to improve distribution instead of something we have in our data already.
Let’s revist our example from Part One, where all the following records were ending up in the same partition.
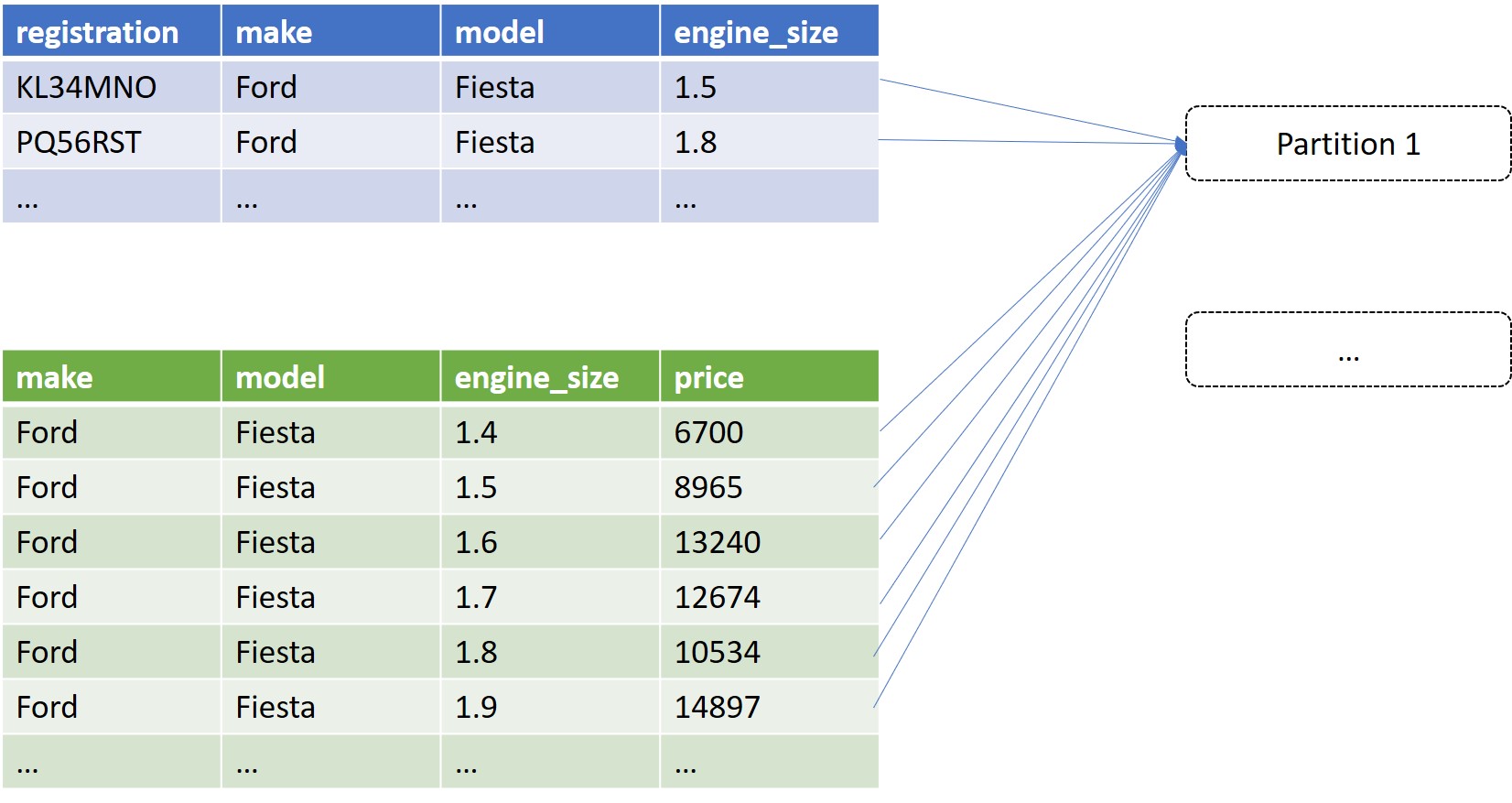
Now, instead of exploding t1 with the engine_size, let’s add a new column, called skew_key. For the purpose of this example, let’s have skew_key range from 0 - 2. We now want three rows for each original row from t1, all with different values for skew_key.
How does this help? We also need to add skew_key to t2 so it can be used in the join. For this, we simply assign each row in t2 a random value in the range 0 - 2.
Now everything with the same make and model will still be joined as desired (if you’re not conviced that the result is the same, maybe draw it out on paper). However, we will have a more even partition distribution.
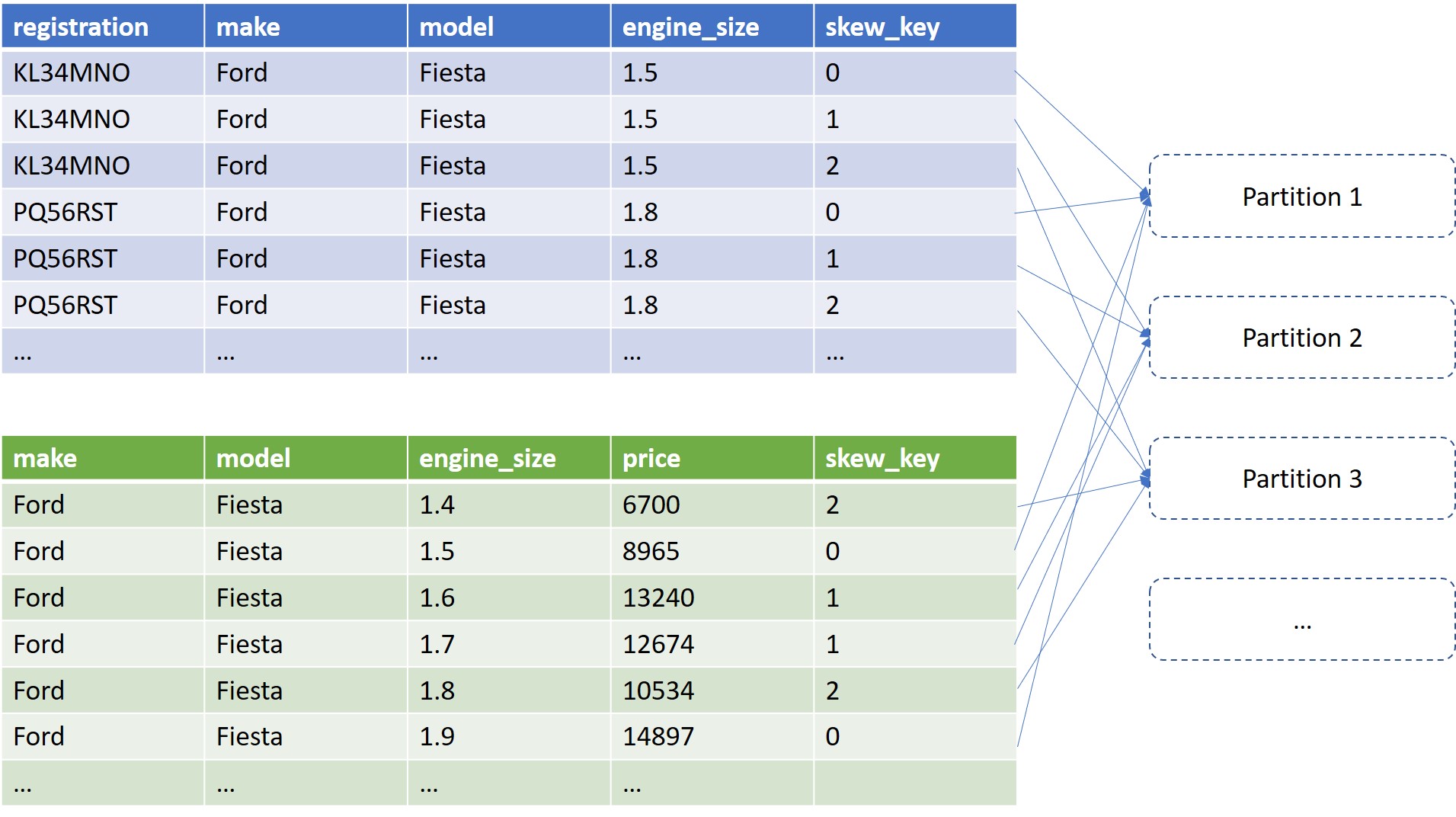
It’s worth noting that for our specific example where we’re also filtering on an inequality involving engine_size, this partition distribution isn’t as good as the engine_size explosion we did in Part One for the same amount of additional data. However, for the general case it works nicely.
Let’s do this is Spark, and see how well it works in practice.
//Because our datasets are small, Spark will try and do a broadcast join. In order to see our skew happening, we need to suppress this behaviour
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val t1WithSkewKey = t1.withColumn("skew_key", explode(lit((0 to 2).toArray)))
val t2WithSkewKey = t2.withColumn("skew_key", monotonically_increasing_id() % 3)
val nonSkewedResult = t1WithSkewKey.join(t2WithSkewKey, Seq("make", "model", "skew_key"))
.filter(abs(t2("engine_size") - t1("engine_size")) <= BigDecimal("0.1"))
.groupBy("registration")
.agg(avg("sale_price").as("average_price")).collect()
Hmm, if we look at the Spark UI, this is not great. We still have a skew - it’s over 3 partitions now and isn’t as bad as before but it’s definitely still there.
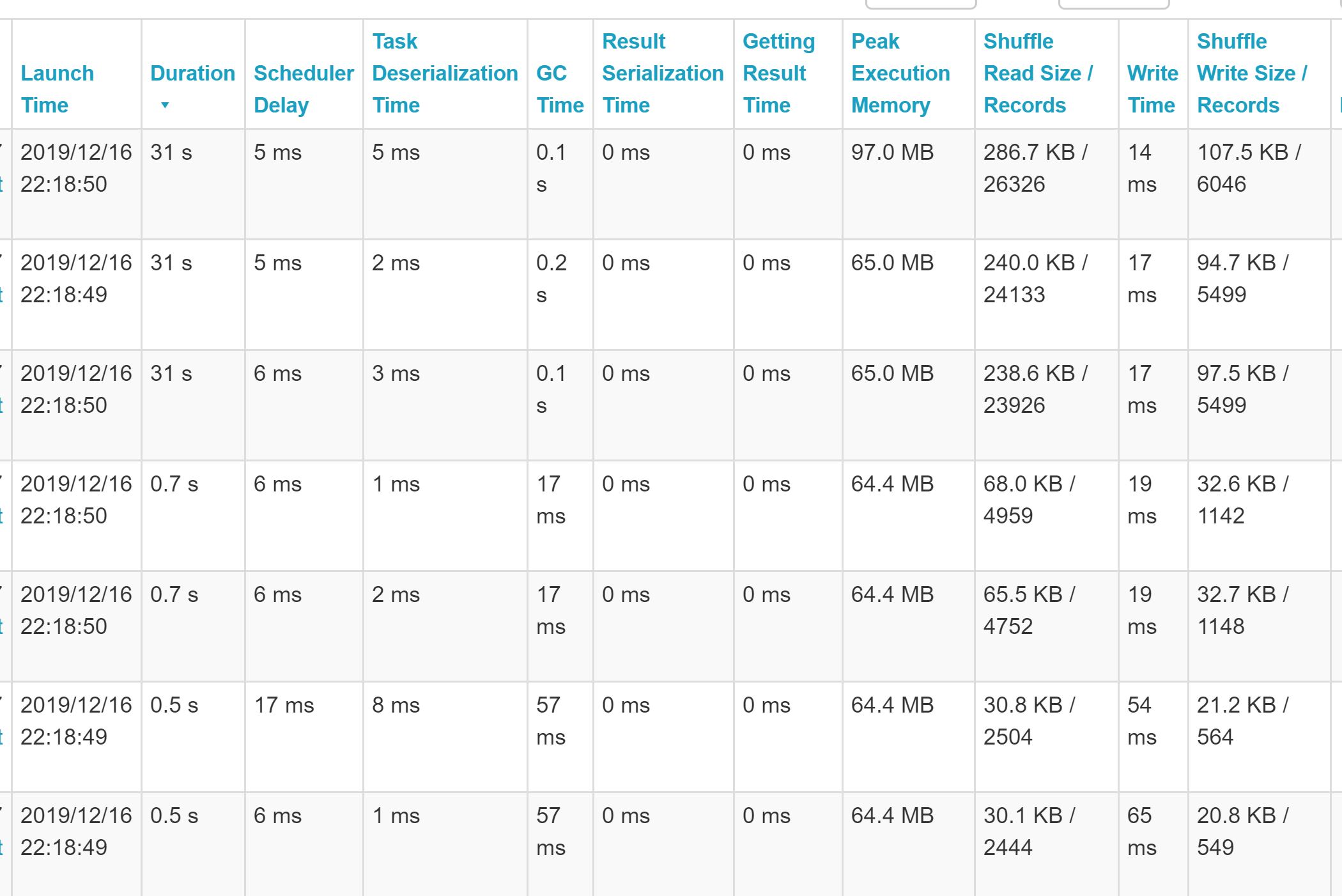
It looks like distributing our skewed data over three partitions isn’t enough - let’s whack it right up to 200 and see if that helps.
//Because our datasets are small, Spark will try and do a broadcast join. In order to see our skew happening, we need to suppress this behaviour
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val t1WithSkewKey = t1.withColumn("skew_key", explode(lit((0 to 199).toArray)))
val t2WithSkewKey = t2.withColumn("skew_key", monotonically_increasing_id() % 200)
val nonSkewedResult = t1WithSkewKey.join(t2WithSkewKey, Seq("make", "model", "skew_key"))
.filter(abs(t2("engine_size") - t1("engine_size")) <= BigDecimal("0.1"))
.groupBy("registration")
.agg(avg("sale_price").as("average_price")).collect()
Looking at the Spark UI, that’s much better! As you can see, the data is pretty evenly distributed now.
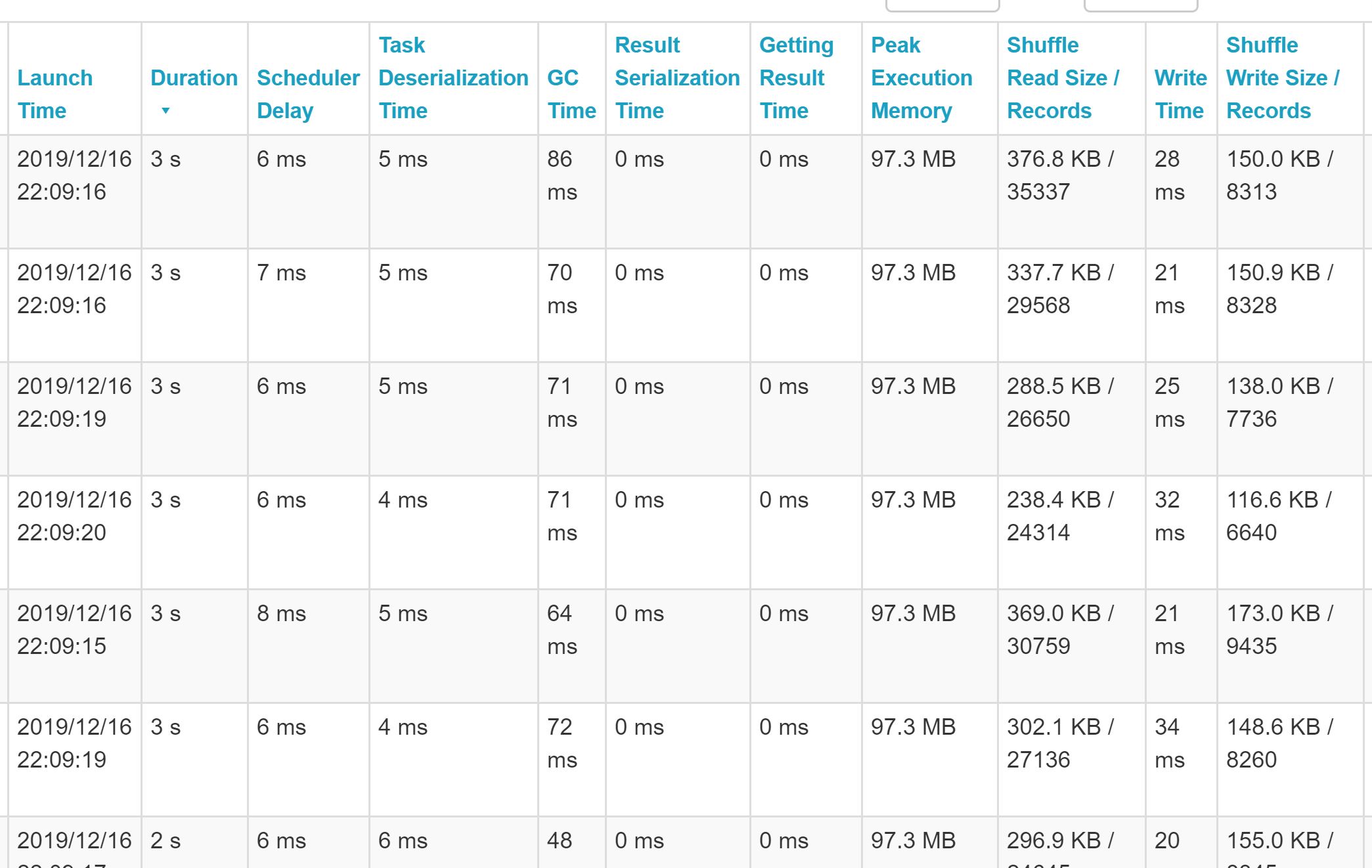
We’ve got a lot more of it now though (we’re making t1 200 times bigger than it’s original size). As this data is small, we’re not seeing any problems, but if you have a lot of data to begin with, you could start seeing things slow down due to increased shuffle write time. As with everything in the Big Data world, there’s normally a sweet spot somewhere, it just takes a bit of experimentation and fine-tuning.
We can help ourselves quite a lot here by only exploding what we need to. In the above examples we were exploding absolutely every record in t1 with all possible values for skew_key, however we only actually need to do this for those records which are skewing. For the non-skewing records we can just assign a static skew_key of 0 every time.
//Because our datasets are small, Spark will try and do a broadcast join. In order to see our skew happening, we need to suppress this behaviour
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val t1WithSkewKey = t1.withColumn("skew_key", explode(when($"make" === "FORD" && $"model" === "FIESTA", lit((0 to 199).toArray)).otherwise(array(lit(0)))))
val t2WithSkewKey = t2.withColumn("skew_key", when($"make" === "FORD" && $"model" === "FIESTA", monotonically_increasing_id() % 200).otherwise(lit(0)))
val nonSkewedResult = t1WithSkewKey.join(t2WithSkewKey, Seq("make", "model", "skew_key"))
.filter(abs(t2("engine_size") - t1("engine_size")) <= BigDecimal("0.1"))
.groupBy("registration")
.agg(avg("sale_price").as("average_price")).collect()
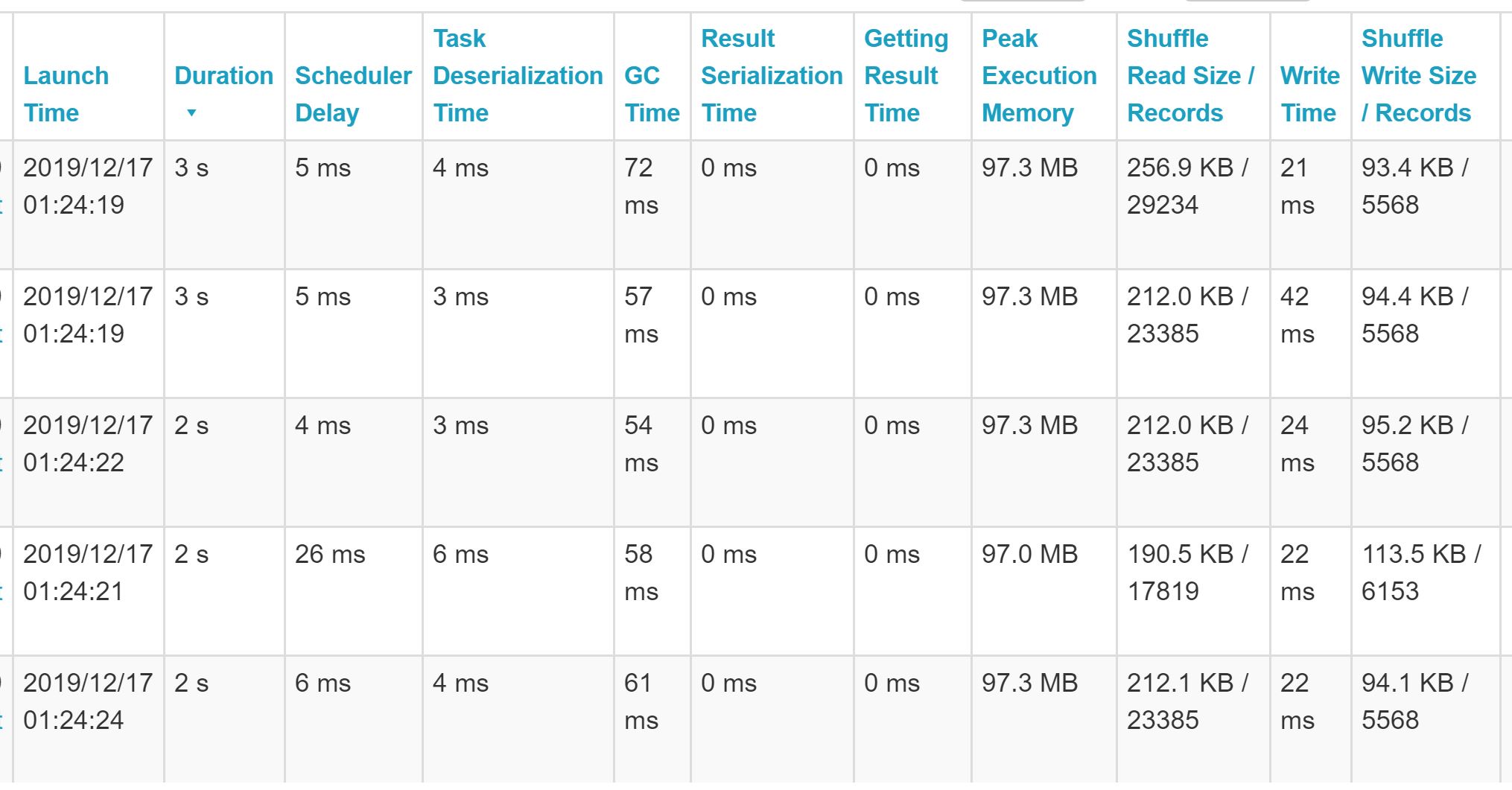
If we look at the UI now, we can see that again we have well-distributed data, but we’re dealing in significantly smaller volumes which ultimately helps with performance.
That’s almost it from me on the subject of data skews. I hope these two posts have been useful and help you to avoid some of the pain we went through! If you think you have a skew, work through the following steps:
- Where is the skew? (for us, this was easy - Ford Fiestas of course!)
- Do you have inequalities in the join condition, or inequality filters after the join? If yes, do these columns contain discrete data? If yes, consider doing explosion on them like in Part One.
- If no to the above, or you need something more, use a skew_key as detailed in this post. Be careful to only explode on the skewed records to avoid generating unnecessary data.
Happy skew fighting!