
Business Intelligence
Daniel Timar
Analyst
Jonathan Cooper
Analyst
Data Engineering
Vicky Avison
Lead Data Engineer
Alex Bush
A Hadoop specialist with a penchant for DevOps practices
Data Science
David Asboth
Data Scientist, former Software Developer, occasional content creator
Michael O'Rourke
Business Intelligence
Our Journey to self-service and beyond

A tale of self service enlightenment.
Comparing Apples to Oranges: The Dangers of Estimating Effects

Working with Manheim, a Cox Automotive brand that provides vehicle auctions, inspections, transport and reconditioning, we are often asked about the potential effect of certain attributes of vehicles on the final sale price.
Data Engineering
The Taming of the Skew - Part Two
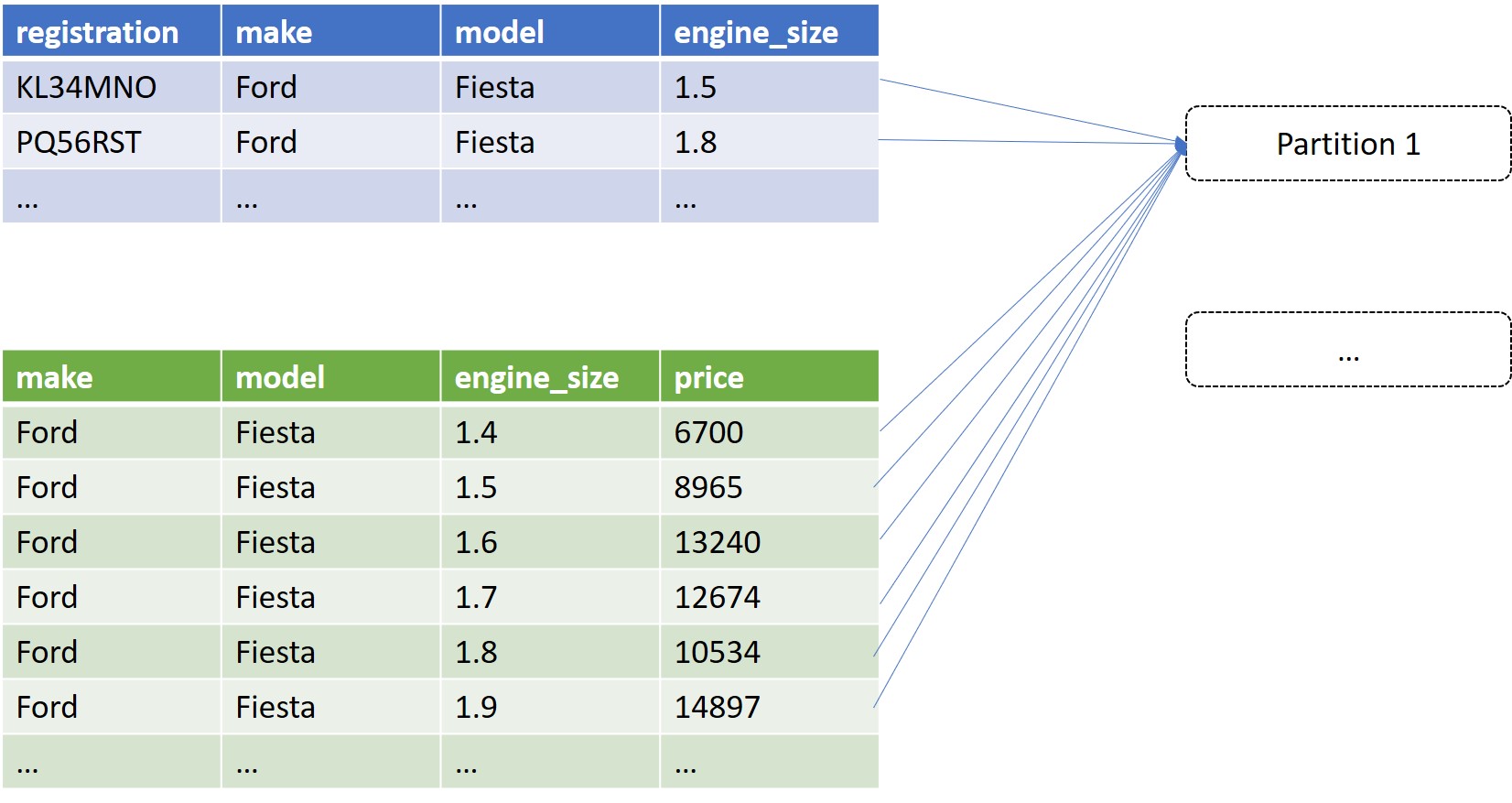
This is a continuation of The Taming of the Skew - Part One. Please read that first otherwise the rest of this post won’t make any sense!
The Taming of the Skew - Part One
If you’ve done many joins in Spark, you’ve probably encountered the dreaded Data Skew at some point. The initial elation at how quickly Spark is ploughing through your tasks (“Wow, Spark is so fast!”) is later followed by dismay when you realise it’s been stuck on 199/200 tasks complete for the last 5 hours.
Data Science
We were promised electric cars and jetpacks

Electric vehicles have been lauded as a silver bullet for many of today’s impending catastrophes. Even with all their potential benefits we are still waiting for the electric car revolution to start. So, why aren’t consumers making the switch to electric vehicles?
How do you keep your sanity when working on a long-term project?

Projects (and your involvement in them) come in all shapes and sizes. Some are like a Michael Mann bank heist; you’re in and out, never to be heard of again. Others are like a relationship. You know you’re going to be spending most of your time with them and even when you’re not together, they’re never far from your thoughts.
To accuracy… and beyond

In Data Science, when you learn about how to predict the future with machine learning, you are presented with an optimisation problem. The central focus of machine learning, at least the subset called “supervised learning”, is to ask “what is the best way to predict Y using X?” where “best” has a specific meaning. When you have past examples to learn from, “best” is some sort of measure of accuracy. How well did this particular model predict Y using X, when we can check it against past examples? Whether this is a classification task, where you’re trying to put things into the right category, or regression, where you are trying to get as close to a continuous number as you can, the higher the accuracy the better your model. There are ways to guard against complacency to ensure you’re not just learning the particulars of your dataset, but ultimately you are trying to get as high an accuracy score as possible.
30 years of change in engines

Engine design has changed a great deal since the Model T. Forced induction in 1920s increased engine power without increasing the size; fuel injection in the 1980s increased fuel efficiency and made carburettors a thing of the past; and more recently, the introduction of hybrid engines has massively reduced CO2 emissions.
From Laptop to Cluster: Our Journey to Big Data

As the world accumulates data, more and more data science teams will be faced with the problem that their data no longer fits into their conventional workflow. Creating data-driven systems with hundreds of millions of rows of data requires a different set of tools to the ones statisticians, and even software developers, have been using in recent decades. How do we at Cox Automotive envisage moving from laptop-based analyses to big data systems?